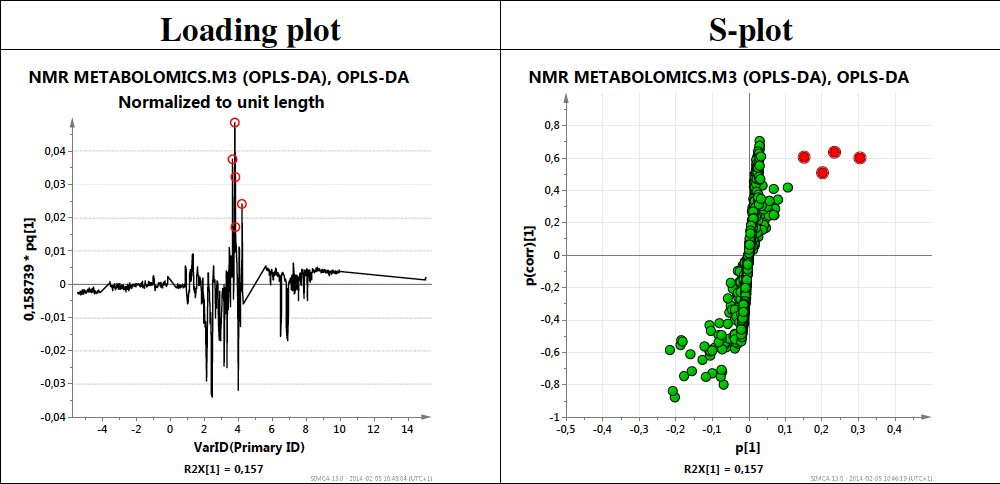
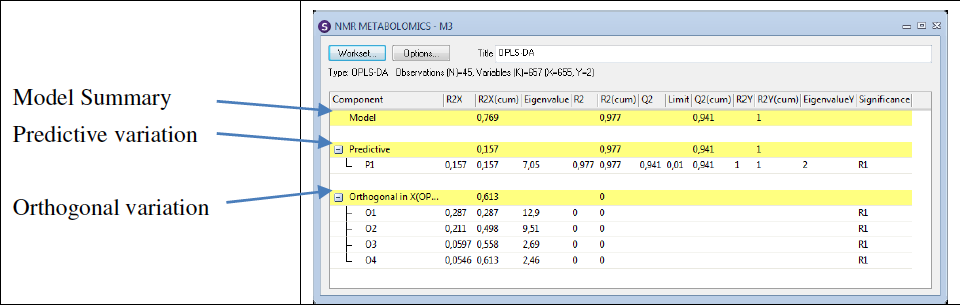
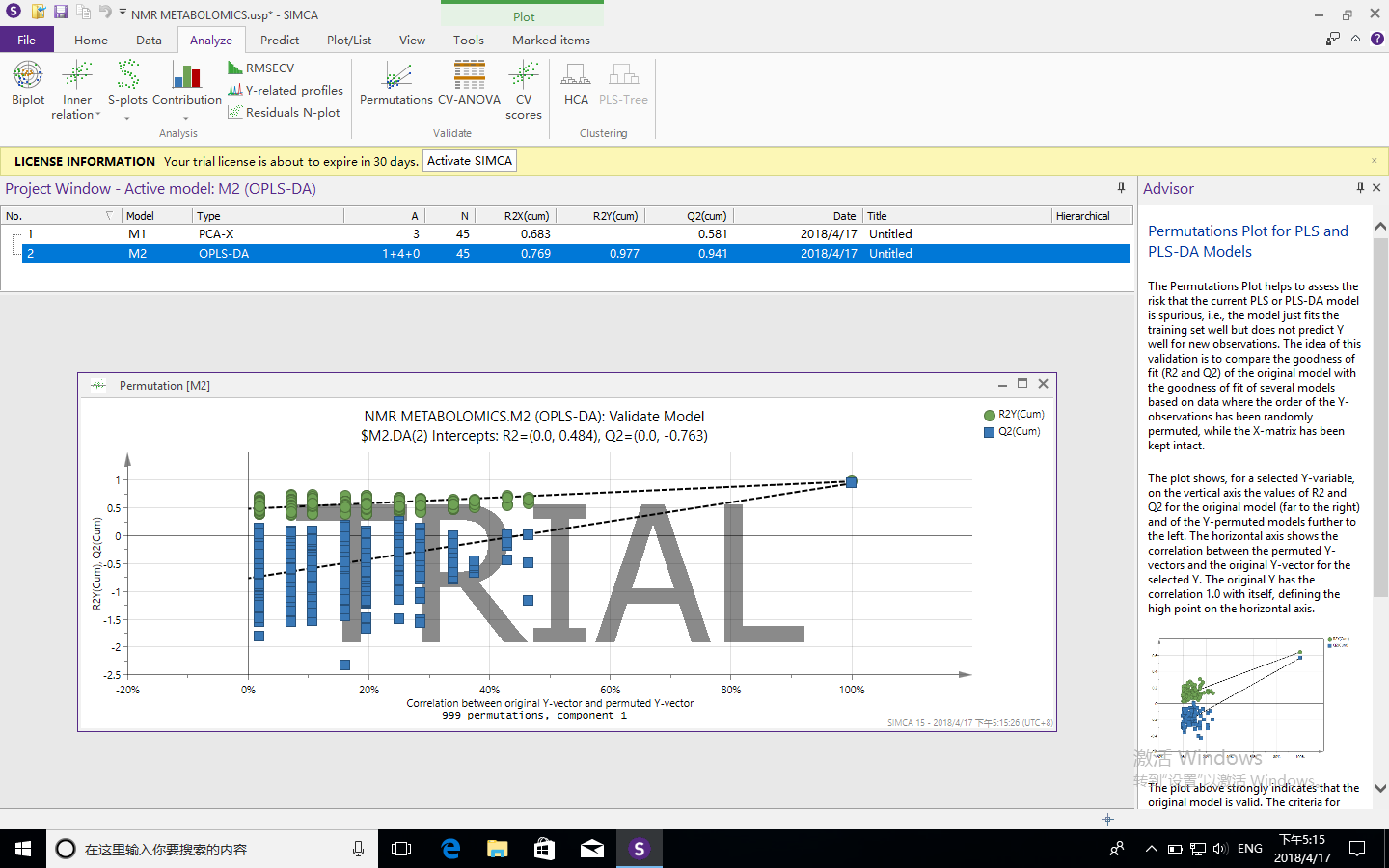
翻译
好长,怕有两三百字,关于维A的
关于Iron的一段很长文字
关于维生素A稳态(homeostasis)的一大段话
关于dietary protein 和bone 关系的一段文字。
绪论
- 营养与食品卫生学 nutrition & food hygiene
预防医学领域内,主要研究膳食与机体的相互作用及其对健康的影响和作用机制,据此提出预防疾病和促进健康的措施、政策和法规等。
- 营养
机体从外界摄取食物,经过体内的消化、吸收和(或)代谢后,参与构建组织器官,满足生理功能或体力活动需要的必要的生物学过程。
- 营养学 nutrition science
研究食物中对人体有益的成分,以及人体摄取和利用这些成分以维持和促进健康的规律和机制,并在此基础上,采取具体的、宏观的、社会性措施,以改善人类健康,提高生命的质量的科学。
试述食品卫生学的定义和研究内容 @@@
- 食品卫生学 food hygiene @@@@
研究食品中可能存在的、危害人体健康的有害因素,及其对机体的作用规律和机制,并在此基础上,提出具体、宏观的预防措施,以提高食品卫生质量,保护食用者安全的科学。
食品卫生学的研究内容 @@@
- 食品的污染
- 食品及其加工技术的卫生问题
- 食源性疾病及食品安全评价体系的建立
- 食品安全监督管理
- 食品安全风险监测和预警
营养学
基础营养学
- 营养素(nutrient):
为维持机体繁殖、生长发育和生存等一切生命活动和过程,需要从外界环境中摄取的物质。
水的生理功能:
- 构成细胞和体液的重要组成部分
- 参与新陈代谢
- 调节体温
- 润滑作用
- 合理营养(rational nutrition):
是指人体每天从食物中摄入的能量和各种营养素的数量和相互之间的比例,能满足在不同生理阶段、不同劳动环境和不同劳动强度下的需要,并使机体处于良好的健康状态。
- 营养不良(malnutrition):
是指由于一种或一种以上营养素的缺乏或过剩所造成的机体健康异常或疾病状态。
包括营养缺乏(nutrition deficiency)和营养过剩(nutrition excess)。
- 膳食营养素参考摄入量(dietary reference intakes, DRIs):@
是为了保证人体合理摄入营养素,避免缺乏和过量,再推荐膳食营养素供给量(recommended dietary allowance, RDA)的基础上发展起来的每日平均膳食营养素摄入量的一组参考值。
- 平均需要量(estimated average requirement, EAR):
是指某一特定性别、年龄和生理状态群体中的所有个体对某种营养素需要量的平均值。
EAR是制定RNI的基础,可用于评价和计划群体的膳食摄入量,或判断个体某营养素摄入量不足的可能性。 - 推荐摄入量(RNI):@
是指可以满足某一特定性别、年龄和生理状态群体中绝大多数个体(97~98%)需要量的某种营养素摄入水平。
RNI可作为个体每日摄入某种营养素的推荐值/目标值。 # 能量需要量EER等于能力EAR。 - 适宜摄入量(adequate intake, AI):
AI是通过观察或实验获得的健康人群某种营养素的摄入量。
AI与RNI一样可作为目标人群中个体每日摄入某种营养素的推荐值/目标值,但准确性不如RNI,可能偏高。 - 可耐受最高摄入量(tolerable upper intake level, UL):
是营养素或事物成分每日摄入量的安全上限,即一个健康人群中几乎所有个体都不会产生毒副作用的最高摄入量。 - 宏量营养素可接受范围(acceptable macronutrient distribution ranges, AMDR)
- 预防慢性非传染性疾病的建议摄入量(proposed intakes for preventing non-communicable chronic diseases, PI-NCD)
- 特定建议值(specific proposed levels, SPL)
- 合理膳食(rational diet):@
又称平衡膳食(balanced diet),是指提供给机体种类齐全、数量充足、比例合适的能量和各种营养素,并与机体的需要保持平衡,进而达到合理营养、促进健康、预防疾病的膳食。是实现合理营养的物质基础和唯一途径。
合理膳食要求:
- 食物种类齐全,数量充足,比例合适
- 保证食物安全
- 科学的烹调加工
- 合理的进餐制度和良好的饮食习惯
- 遵循《中国居民膳食指南》的原则
蛋白质
- 必需氨基酸(essential amino acid): 是指人体内不能合成或合成速度不能满足机体需要,必须从食物中直接获得的氨基酸。
“携一两本单色书来” + 组氨酸(婴儿)
- 非必需氨基酸:人体可以自身合成,不一定需要从食物中直接供给的氨基酸。
- 条件必需氨基酸(conditionally essential amino acid):@
某些氨基酸在正常情况下能够在体内合成,为非必需氨基酸;但在某些特定条件下,由于合成能力有限或需要量增加,不能满足机体需要,需要从食物中获取,变成必需氨基酸,即条件必需氨基酸。
- 氨基酸模式(amino acid pattern):
蛋白质中各种必需氨基酸的构成比例。 # 将色氨酸含量定为1。
- 限制氨基酸(limiting amino acid):
含量相对较低的必需氨基酸称为限制氨基酸。其中含量最低的称为第一限制氨基酸,余者依此类推。
- 参考蛋白(reference protein):
指可用来测定其他蛋白质质量的标准蛋白。
鸡蛋因其蛋白质与人体蛋白质氨基酸模式最接近,在试验中常以它作参考蛋白。
- 优质蛋白质/完全蛋白质:
含必需氨基酸种类齐全,氨基酸模式与人体蛋白质氨基酸模式接近的蛋白质,营养价值较高。不仅可以维持成人健康,也可促进儿童生长发育。
如蛋、奶、肉、鱼等动物性蛋白质及大豆蛋白等。
- 半完全蛋白质:
虽含有种类齐全的必需氨基酸但氨基酸模式与人体蛋白质氨基酸模式差异较大,其中一种或几种必需氨基酸相对含量较低,导致其他的必须氨基酸在体内不能被充分利用而被浪费,虽可维持生命但不能促进生长发育的蛋白质。
如大多数植物蛋白。
- 蛋白质的互补作用(protein complementary action):@
为了提高植物性蛋白质的营养价值,将两种或两种以上的食物混合食用,从而达到以多补少,提高膳食蛋白质营养价值的目的。这种食物间互相补充其氨基酸不足的作用称为蛋白质互补作用。
蛋白质的功能:
- 人体组织的构成成分:瘦组织,肌肉,骨骼牙齿胶原蛋白,指甲,细胞结构等。
- 构成体内各种重要的生理活性物质,调节生理功能:酶,激素,抗体,转运体;渗透压,酸碱度。
- 供给能量
- 肽类的特殊生理功能:免疫调节,促进矿物质吸收,降血压,清除自由基。
食物蛋白质营养学评价 @
(1)蛋白质含量:凯氏定氮法等
(2)蛋白质消化率
- 蛋白质消化率 (digestibility):
蛋白质消化率不仅反应蛋白质在体内被分解的程度,同时还反应消化后氨基酸和肽被吸收程度。 - 真消化率(true ):
TD=[食物氮-(粪氮-粪代谢氮)]÷食物氮×100%
(粪代谢氮,是指肠内源性氮,是在试验对象完全不摄入蛋白质时,粪中含氮量。) - 表观消化率(apparent digestibility):
在实际应用中,常不考虑粪代谢氮。这样不仅实验方法简便,且因所测结果比真消化率要低,具有安全性。这种消化率叫做表观消化率。AD=(食物氮-粪氮)÷食物氮×100%
(3)蛋白质利用率 - 生物价(Biological value, BV):@
蛋白质生物价是反映食物蛋白质消化吸收后,被机体利用程度的指标,生物价的值越高,表明其被机体利用程度越高,最大值为100。 - 蛋白质净利用率(net protein utilization, NPU):@@
蛋白质净利用率是反应食物中蛋白质被利用的程度。此项指标包括食物蛋白质消化和利用,故更为全面。
蛋白质净利用率(%)=消化率×生物价=储留率÷食物氮×100 - 蛋白质功效比值(protein efficiency ratio, PER) :
蛋白质功效比值测定,是用处于生长阶段的幼年动物(一般用刚断奶的雄性大白鼠),以其在实验期内体重增加和摄入蛋白质的量的比值,作为反映蛋白质营养价值的指标。
蛋白质功效比值=动物体重增加(g)/摄入食物蛋白质(g) - 氨基酸评分 (amino acid score, AAS):
是最简单的评估蛋白质质量的方法。该法是用被测食物蛋白质必需氨基酸评分模式和推荐的理想模式或参考蛋白模式进行比较。
氨基酸评分=(被测蛋白质每克氮(或蛋白质)中必需氨基酸量(mg))/(理想模式或参考蛋白中每克氮(或蛋白质)中相应的必需氨基酸量(mg))×100 - 经消化率修正的氨基酸评分(protein digestibility corrected amino acid score, PDCAAS):
经消化率修正的氨基酸评分=氨基酸评分×真消化率 - 其他指标:相对蛋白质值,净蛋白质比值和氮平衡指数等。
- 蛋白质-能量营养不良(protein-energy malnutrition, PEM):
- Kwashiorkor,指能量摄入基本满足而蛋白质严重不足的儿童营养性疾病,主要表现为腹腿部水肿、虚弱、表情淡漠、生长滞缓、头发变色、变脆和易脱落、易感染其他疾病等;
- Marasmus,原意即为“消瘦”,指蛋白质和能量摄入均严重不足的儿童营养性疾病,患儿消瘦无力,因易感染其他疾病而死亡。
蛋白质摄入过多的危害:
- 过多动物性蛋白质的摄入,必定伴有较多动物脂肪和胆固醇的摄入
- 加重肾脏负荷
- 含硫氨基酸摄入过多,加速骨骼中钙的流失,易产生骨质疏松症
- 同型半胱氨酸可能是心脏疾病的危险因素
蛋白质营养状况评价:
- 血清蛋白质
- 上臂肌围和上臂肌区:评价总体蛋白质储存比较可靠的指标
- 血清氨基酸比值
- 氮平衡(nitrogen balance):
摄入蛋白质的量和排出蛋白质的量之间的关系称为氮平衡。
氮平衡关系式如下:B=I-(U+F+S),
B:氮平衡;I:摄入量;U:尿素;F:粪氮;S:皮肤等氮损失。
脂肪
脂质的功能
(1)体内脂肪的生理功能:
- 贮存和提供能量
- 保温及润滑作用
- 节约蛋白质作用
- 机体构成成分:细胞膜
- 内分泌作用:瘦素、TNF-α、IL-6、IL-8、雌激素、IGF-1等。
(2)食物中脂肪的作用:
提供能量,作为人体脂肪的合成材料 - 增加饱腹感 脂肪进入十二指肠时,刺激十二指肠产生肠抑胃素,使胃蠕动受到抑制。
- 改善食物的感观性状
- 提供脂溶性维生素:脂肪不仅是脂溶性维生素ADEK来源,也可促进其吸收。
(3)类脂的功能(磷脂 & 胆固醇) - 提供能量
- 细胞膜成分:双重特性,利于细胞内外物质交换。
- 乳化剂功能:脂肪悬浮,促进脂肪吸收、转运、代谢。
- 改善心血管功能:防止胆固醇沉积、降低血黏度,预防心血管疾病。
- 改善神经系统功能:释放胆碱,乙酰胆碱,促进和改善大脑组织和神经系统的功能
- 胆固醇是细胞膜的重要成分
- 胆固醇可合成激素和VitD3等。
- 必需脂肪酸(essential fatty acid, EFA):
人体不可缺少且自身不能合成,必须通过食物供给的脂肪酸。
EFA包括亚油酸(n-6)和α-亚麻酸(n-3)。
- 构成磷脂的组成成分:构成细胞膜
- 前列腺素合成的前体:血管舒缩、神经传导等
- 参与胆固醇代谢:体内约70%胆固醇与脂肪酸酯化
膳食脂肪的营养学评价
- 脂肪的消化率:熔点
- 必需脂肪酸含量
- 各种脂肪酸的比例
- 脂溶性维生素含量
碳水化合物
– 膳食纤维(dietary fiber):@
主要包括纤维素、木质素、抗性低聚糖、果胶、抗性淀粉以及其他在人类小肠内不可消化的多糖类碳水化合物。
主要来源于全谷类、蔬菜水果等
生理学意义:促进肠道健康功能。(见碳水化合物的功能第5条)
- 益生元:
指不被人体消化系统消化和吸收,能够选择性地促进宿主肠道内原有的一种或几种有益细菌(益生菌)生长繁殖的物质。通过有益菌的繁殖增多,抑制有害细菌生长,从而达到调整肠道菌群的目的,促进机体健康的目的。
如乳果糖和异麦芽低聚糖。
- 食物血糖生成指数 (glycemic index,GI):@@@@
简称生糖指数,是反映食物引起人体血糖升高程度的指标,是人体进食后机体血糖生成的应答状况。
GI=某事物摄入后2小时血糖曲线下面积 / 等量葡萄糖摄入后2小时血糖曲线下面积 × 100%
可以衡量某种食物或某种膳食组成对血糖浓度的影响。
- 血糖负荷(glycemic load, GL):
评价某种食物摄入量对人体血糖影响的程度。
GL= 摄入食品中碳水化合物的重量×食品的GI值/100
碳水化合物的功能
- 提供能量
- 构成组织结构及生理活性物质
- 血糖调节作用
- 节约蛋白质作用和抗生酮作用
- 膳食纤维的促进肠道健康功能 @
- 增加饱足感:吸收水份,增加胃内的食物体积
- 促进排便:吸水增加粪便体积,机械刺激肠壁蠕动
- 降低血糖和血胆固醇:减少小肠对糖的吸收,吸附肠道中脂质降低吸收率
- 改变肠道菌群:促进某些有益菌群的增殖
能量
- 能量系数/热价(calorific coefficient/calorific value):
每克宏量营养素(产能营养素:碳水化合物、脂肪和蛋白质)在体内氧化分解(或在体外燃烧)所产生的能量值。
人体的能量消耗
- 基础代谢(basal metabolism):
又称基础能量消耗(BEE):用于维持机体最基本的生命活动所需要的能量消耗,占人体总能量消耗的60~70%
- 基础代谢率(basal metabolic rate,BMR):每小时每平方米体表面积(或每千克体重)的基础能量消耗
BEE的影响因素:体型与体质、生理和病理状况、生活和作业环境
- 身体活动(physical activity):
是指任何由骨骼肌收缩引起能量消耗的身体运动,约占人体总能量消耗的15~30%
影响因素:肌肉发达、体重越重、工作越不熟练者,消耗能量越多 - 食物热效应(thermic effect of food, TEF):
人体在摄食过程中所引起的额外能量消耗,是摄食后发生的一些列消化、吸收活动以及营养素和其代谢产物之间相互转化过程所消耗的能量,又称食物特殊动力作用(specific dynamic action, SDA) - 特殊生理阶段的能量消耗:孕期组织生长及儿童生长发育
-影响基础代谢能量消耗的因素 @
- 体型与体质
- 生理和病理状况
- 生活和作业环境
- 能量需要量(estimated energy requirement, EER):
是指能长期保持良好的健康状态,维持良好的体型、机体构成和理想活动水平的个人或人群,达到能量平衡时所需要的膳食能量摄入量。可以直接等同于相应人群的能量平均需要量(EAR)。
能量摄入的调节
- 神经生理对摄食的调节:通过摄食系统和饱食系统调节摄食启动和终止
- 营养素及其代谢产物对摄食的调节:调控摄食信号因子和饱食信号因子
- 蛋白和肽类因子对摄食的调节:组织细胞中生长素释放肽、胰多肽,瘦素、胆囊收缩素分别促进和抑制食欲和能量代谢;神经肽Y,食欲肽A、B促进和抑制食欲和能量代谢;饱腹因子,促肾上腺皮质激素释放激素抑制摄食行为
- 蛋白因子对能量消耗的影响:解耦联蛋白,β3-肾上腺素受体促进产热和能量消耗
- 非生理因素对能量摄入的影响:进食环境,食物特性,饮食习惯,食物信念和态度,社会文化因素等
矿物质
矿物质的特点
- 矿物质在体内不能合成,必须从外界摄取;
- 矿物质是唯一可以通过天然水途径获取的营养素;
- 矿物质在体内分布极不均匀;
- 矿物质之间存在协同或拮抗作用;
- 某些微量元素在体内的生理剂量与中毒剂量范围较窄,摄入过多易产生毒性作用。
人体矿物质的缺乏与过量的原因?P79
- 地球环境因素:如地方病
- 食物成分及加工因素;
- 人体自身因素:摄入不足、需求增加、疾病状态
- 钙稳态(calcium homeostasis):
当血钙水平降低时,甲状旁腺激素PTH会促使骨骼释放可交换钙,并刺激维生素D转变为活性型1,25-(OH)2-D3,协同PTH的溶骨作用,促进肠粘膜对钙的吸收,促进肾小管对钙的重新收,使血钙水平恢复正常;当血钙水平升高时,降钙素CT可拮抗PTH的溶骨作用,抑制破骨细胞生成,促进成骨细胞产生,从而抑制骨基质的分解和骨盐溶解,促进骨盐沉积,降低血钙水平,使血清钙浓度保持恒定,以维持钙的内环境稳定,成为钙稳态。
钙的生理功能 @@@
- 构成骨骼和牙齿的成分
- 维持神经和肌肉的活动
- 促进细胞信息传递
- 参与凝血过程
- 调节机体酶的活性
- 维持细胞膜的稳定性
- 其他功能:参与激素分泌,维持酸碱平衡,调节细胞正常生理功能
钙的良好膳食来源 @@@
- 奶和奶制品含钙丰富且吸收率高,是食物中钙的良好来源;
- 小虾皮、大豆、海带、芝麻、黑木耳、绿色蔬菜、坚果类等含钙也丰富。
影响钙吸收的因素
- 机体因素:年龄增加摄钙率降低,特殊生理期(孕期,哺乳期),摄钙不足,反射性促进维生素D水平
- 膳食因素:植物有机酸,膳食纤维糖醛酸残基,蛋白质中某些氨基酸,乳糖发酵产酸
- 其他因素:青霉素等抗生素促进钙的吸收
婴儿钙吸收率大于成人的原因 @@@
- 机体因素:钙吸收率受年龄的影响,随着年龄增长,钙吸收率下降;
- 膳食因素:婴儿在4-6月以前膳食以母乳为主,含丰富的蛋白质、乳糖,其在肠道内
的分解、消化可以促进钙吸收;成人膳食结构复杂,植物性食物中的草酸、磷酸、植酸
及膳食纤维等均可阻碍钙吸收; - 其他因素:婴儿对钙的需求较成人高且其肠道对钙的吸收活跃。
影响钙排泄的因素
- 机体因素:血钙浓度,绝经期,补液,酸中毒,激素
- 膳食因素:钠,蛋白质,咖啡因
铁的生理功能
- 参与体内氧的运输和细胞呼吸过程
- 维持正常的造血功能
- 参与其他重要功能:免疫,催化合成,肝脏解毒,抗脂质过氧化
血红素铁 - 动物性食物;非血红素铁 - 植物性食物
影响铁吸收的因素
- 机体因素:营养状况,生理与病理改变,胃肠道pH
- 膳食因素:血红素铁,蛋白类食物,维生素C等,有机酸促进;金属及EDTA,植酸、单宁、多酚物质抑制
- 其他:肠道微生物的某些分解产物抑制铁的吸收
锌的生理功能
- 金属酶的组成成分或酶的激活剂
- 促进生长发育
- 促进机体免疫功能
- 维持细胞膜结构
- 其他:增进食欲,保护皮肤和视力
硒的生理功能
- 抗氧化功能:谷胱甘肽过氧化物酶
- 保护心血管和心肌的健康:克山病
- 增强免疫功能:IL-2
- 有毒重金属的解毒作用
- 其他:促进生长,抗肿瘤
维生素
- 维生素(Vitamin):
是维持机体活动过程所必需的一类微量低分子有机物,在生理上既不是构成各种组织的主要原料,也不是体内的能量来源,但却在机体物质和能量代谢过程中发挥着重要作用。
维生素缺乏的原因
- 摄入不足:食物短缺,选择不当,加工、储藏不当
- 吸收利用降低:老年人,疾病状态
- 维生素需要量相对增高:特殊生理状态
维生素A的生理功能
- 构成视觉细胞内感光物质:视紫红质
- 调节细胞生长和分化
- 维护上皮组织细胞的健康
- 免疫功能
- 抗氧化功能
- 抑制肿瘤生长
维生素D的生理功能
- 促进小肠对钙的吸收
- 促进肾小管对钙、磷的重吸收
- 对骨细胞呈现多种作用
- 通过维生素D内分泌系统调节血钙平衡
- 参与机体多种功能的调节
维生素B1的生理功能 @
- 辅酶功能:焦磷酸硫胺素TPP,氧化脱羧酶的辅酶,转酮醇酶的辅酶
- 非辅酶功能:胆碱酯酶抑制剂,辅助消化药
我国居民缺乏维生素B1的主要原因 @
- 谷类加工去掉了谷皮、糊粉层和胚
- 米、面碾磨过于精细
- 过分淘米,烹调中加碱
维生素B2的生理功能 @
- 参与体内生物氧化与能量代谢
- 参与烟酸和维生素B6的代谢
- 其他生理功能:FAD作为谷胱甘肽还原酶的辅酶抗氧化,FAD与细胞色素P450结合参与药物代谢
-我国居民缺乏维生素B2的主要原因 @
- 谷类加工去掉了谷皮、糊粉层和胚
- 食品加工过程中加碱
- 储存和运输过程中日晒及不避光
- 食物烹调方式:碗蒸米饭比捞饭损失少,烹调肉类时油炸和红烧损失较多
叶酸的生理功能
- 参与嘌呤和嘧啶核苷酸的合成
- 催化二碳氨基酸和三碳氨基酸的相互转化
- 在某些甲基化反应中起重要作用
- 许多生物和微生物生长所必需
维生素C的生理功能
- 抗氧化作用
- 作为羟化过程底物和酶的辅助因子
- 改善铁、钙和叶酸的利用
- 促进类固醇的代谢
- 清除自由基
- 参与合成神经递质
- 其他作用:促进抗体形成,缓解有毒物质毒性
- 植物化学物 phytochemicals
食物中除了含有多种营养素外,还含有其他许多对人体有益的物质,这些植物中食物的生物活性成分是植物能量代谢过程中产生的多种中间或末端低分子量次级代谢产物,具有保护人体、预防心血管病和癌症等慢性非传染性疾病的作用,现已统称为植物化学物。除个别是维生素的前提物质(如β-胡萝卜素)外,其余均为非传统营养素成分,故而过去称为非营养素生物活性成分。
植物化学物的生物活性
- 抑制肿瘤作用
- 抗氧化作用
- 免疫调节作用
- 抑制微生物作用
- 降胆固醇作用
- 其他:降血压、血糖、血小板和血凝以及抑制炎症等作用
各类食品的营养价值
- 食物的营养价值(nutritional value):
某种食物所含营养素和能量能满足人体营养需要的程度。食物营养价值的高低取决于食品中营养素的种类是否齐全、数量的多少、相互比例是否适宜以及是否被人体消化吸收和利用。
食物营养价值的评价及常用指标 @
- 营养素的种类及种类
当评定食物的营养价值,应对其所含营养素的种类及含量进行分析确定。食物中所提供的营养素种类和营养素的相对含量,越接近于人体的需要和组成,该类食物的营养价值就越高。食物所含营养素含量很低,营养素相互之间的比例不当,会影响食物的营养价值。另外食物品种、部位、产地、成熟程度会影响食物中营养素的种类和含量。 - 营养素质量
食物质的优劣可体现在所含营养素被人体消化利用的程度,消化吸收率和利用率越高,其营养价值就越高。INQ是常用的评价食物营养价值的指标。
- 营养质量指数(index of nutrition quality,INQ):@@
是指食物中某营养素能满足人体营养需要的程度(营养素密度)与该食物能满足人体能量需要的程度(能量密度)的比值,是评价食物营养价值的常用指标。
- 营养素在加工烹调过程中的变化
过度加工一般会引起某些营养素损失,但某些食物如大豆通过加工制作可提高蛋白质的利用率。因此食物应选择适当的加工技术。 - 食物抗氧化能力
食物中抗氧化的成分包括抗氧化营养素和植物化学物,抗氧化物质含量高的食物可以认为其营养价值也高。 - 食物血糖生成指数
不同食物来源的碳水化合物进入机体后,因其消化吸收速率不同,对血糖水平的影响也不同,可用GI来评价食物碳水化合物对血糖的影响,从而反应食物营养价值的高低。 - 食物中的抗营养因子
还要考虑食物中存在有抗营养因子,植物性食物中所含的植酸、草酸等可影响矿物质的吸收,大豆中含有蛋白酶抑制剂及植物红细胞凝血素等。 - 食物中植物化学物的含量和种类
评价食物营养价值的意义
- 全面了解各种食物的天然组成成分;发现各种食物的主要缺陷,并指出改造或开发新食品的方向,解决抗营养因子问题,以充分利用食物资源。
- 了解在食物加工过程中食物营养素的变化和损失,采取相应的有效措施,最大限度保存食物中的营养素。
- 指导人们科学选购食物及合理配制平衡膳食,以达到促进健康、增强体质、延年益寿及预防疾病的目的。
谷类结构和营养素分布
- 谷皮:纤维素,半纤维素,矿物质,脂肪
- 糊粉层:蛋白质,脂肪,矿物质,B族维生素
- 胚乳:大量淀粉,一定量蛋白质,少量脂肪、矿物质、维生素
- 胚:脂肪,蛋白质,矿物质,B族维生素和维生素E
谷类的营养成分及特点 @
- 蛋白质:谷类中蛋白质含量一般在7.5%~15%之间,所含必须氨基酸组成不合理,赖氨酸为第一限制氨基酸,营养价值低于动物性食物。
- 碳水化合物:最经济的来源,主要为淀粉,占70%~80%,谷皮中膳食纤维丰富,但加工越精细丢失越多。另外,谷皮中含有丰富的膳食纤维,加工越精细,膳食纤维丢失越多,故全谷类食物是膳食纤维的重要来源。
- 脂肪:含量普遍较低,约1~4%,主要集中在糊粉层和胚芽,加工时易丢失。
- 矿物质:含量为1.5%~3%,主要为磷和钙,多以植酸盐形式存在,消化吸收较差,主要存在于谷皮和糊粉层中,加工容易损失。
- 维生素:谷类是B族维生素摄入的重要来源,如维生素B1、B2、烟酸、泛酸、和维生素B6,主要存在于糊粉层和胚芽中,精加工的谷物其维生素大量损失。
- 植物化学物:黄酮类化合物、酚酸类物质、玉米黄素等。
谷类食品的营养价值:
- 主要成分是碳水化合物
- 精加工米面粉微量营养素丢失较多
- 玉米低聚肽降血压、降血脂
- 小麦低聚肽抑制血管紧张素转化酶ACE,调节免疫,抗氧化
& 结合我国居民目前主要的营养问题分析
大豆的营养价值 @@@
- 蛋白质:大豆的蛋白质含量高达35%~40%,球蛋白、赖氨酸较多,氨基酸模式较好,属于优质蛋白质。
- 脂肪:含量为15%~20%,不饱和脂肪酸占85%,是我国居民主要的烹调用油。
- 碳水化合物:含量为25%~30%,一半为可供人体利用;另一半为人体不能消化吸收的寡糖。
- 微量营养素:含有丰富的钙、铁、维生素B1、B2,维生素E。
- 植物化学物与抗营养因子:大豆异黄酮,大豆皂荚,大豆甾醇,大豆卵磷脂,大豆低聚糖(胀气因子),植酸,蛋白酶抑制剂,植物红细胞凝血素。
蔬菜的营养素种类与特点
- 蛋白质:含量很低
- 脂肪:含量极低
- 碳水化合物:含量差异较大,蔬菜所含纤维素、半纤维素是膳食纤维的主要来源
- 矿物质:丰富的钾,钙,磷,铁,钠,镁,铜等
- 维生素:β-胡萝卜素,维生素C、B2,叶酸等
- 植物化学物:类胡萝卜素,植物固醇,皂苷,芥子油苷,多酚,蛋白酶抑制剂,单萜类,有机硫化物,植酸等
- 抗营养因子和有害物质:植物血细胞凝集素,皂苷,蛋白酶抑制剂,草酸等
水果的营养素种类及特点
- 蛋白质,脂肪含量均不超过1%
- 碳水化合物:含量在6&~28%之间,主要是果糖、葡萄糖和蔗糖
- 矿物质:含有钠、铁、锌、铜等,其中钾、钙、镁、磷较多,
- 有机酸:柠檬酸,苹果酸,酒石酸等
- 植物化学物:花青素,类胡萝卜素,黄酮类物质,多酚类化合物等
畜禽肉类的营养素种类及特点
- 蛋白质:肌肉组织,含量约为10%~20%,属于优质蛋白质
- 脂肪:肥瘦差异较大,以饱和脂肪酸为主,内脏含较高胆固醇
- 碳水化合物:以糖原形式存在于肌肉和肝脏中,含量极少
- 矿物质:血红素铁,肾中富硒,钾钙钠镁磷硫铜锰等
- 维生素:B族维生素,维生素A,内脏尤高
水产品的营养素含量及特点
- 蛋白质:15%~20%,富含亮氨酸和赖氨酸,属于优质蛋白质
- 脂肪:含量低,不饱和脂肪酸丰富,EPA & DHA
- 碳水化合物:糖原,含量低
- 矿物质:含磷最高,海水鱼类含碘丰富,钾钙锌铁硒锰
- 维生素:鱼肝维生素A,D,B2,E,B1,烟酸
乳的营养价值
- 蛋白质:2.8%~3.3%,酪蛋白,乳清蛋白,乳球蛋白,属于优质蛋白质
- 脂类:3%~5%,主要为甘油三酯,脂肪酸组成复杂
- 碳水化合物:乳糖,调节胃酸,促进胃肠蠕动和消化液分泌,促进钙的吸收和肠道乳酸杆菌繁殖
- 矿物质:钙的良好来源,铁含量很低
- 维生素:维生素A,D,C,胡萝卜素,B族维生素,尤B2
- 酶类:促进营养物质的消化
- 有机酸:柠檬酸,微量乳酸等
- 生理活性物质:生物活性肽,乳铁蛋白,免疫球蛋白,激素,生长因子
& 婴儿配方奶粉的基本要求和营养特点 @
(1)营养要求:以母乳的营养素含量及其组成模式为生产依据。参照母乳组成成分和模式对牛奶的组成进行调整,配成适合婴儿生理特点并能满足其生长发育所需的产品。
(2)基本特点:
- 添加与母乳同型的活性顺式亚油酸和适量α-亚麻酸,使其接近母乳中含量及比例。
- α-乳糖与ß-乳糖按4:6的比例添加,适当加入可溶性多糖。
- 脱去牛奶中部分钙、磷、钠盐。
- 强化维生素A、D及适量其他维生素,以促进正常生长发育及预防佝偻病。
- 对牛乳蛋白过敏的婴儿,可用大豆蛋白作为蛋白质来源。
蛋的营养价值
- 蛋白质:10%以上,优质蛋白质,生物学价值最高,参考蛋白
- 脂肪:蛋清中极少,98%集中在蛋黄中,乳化状易消化吸收,蛋黄是磷脂的良好食物来源,卵磷脂降低血胆固醇,促进脂溶性维生素的吸收,胆固醇主要集中在蛋黄
- 碳水化合物:较少
- 矿物质:主要存在于蛋黄,钾钙钠磷,铁锌硒,非血红素铁
- 维生素:主要集中在蛋黄,维生素A,E,B2,B6,D,K,泛酸
坚果的营养价值
- 蛋白质:12%~25%,有些必需氨基酸相对较低
- 脂肪:高达44%~70%,以不饱和脂肪酸为主
- 碳水化合物:含量不一,差异较大
- 微量营养素:维生素E,硒,钾钙锌铁,维生素B1,B6
特殊人群营养
公共营养
- 公共营养(public nutrition):@@
是通过营养调查、营养监测发现人群中存在的营养问题及其影响因素,在此基础上有针对性地提出解决营养问题的措施,以及为提高、促进居民健康而制定指南、政策和法规等。
公共营养是以人群为对象,将营养科学原理、理论和技术应用于指导国民生活的社会实践。
公共营养的特点 @@
- 实践性:基于人群层面开展调查研究和营养干预
- 宏观性:公共营养研究对象是特定的社会群体
- 社会性:涉及社会、经济、法律、文化、行为习惯和宗教信仰等
- 多学科:医学、社会与行为学、经济想、政治等。
- 膳食结构(dietary pattern):@
是一个国家、一个地区或个体日常膳食中各类食物的种类、数量及其所占的比例。
& 我国经济发达地区(大城市)居民的膳食结构:西方经济发达国家膳食结构 @
世界上典型的膳食结构
- 东方膳食结构:以植物性食物为主,动物性食物为辅
发展中国家:中国,巴基斯坦,孟加拉国和非洲一些国家。
特点是谷物食物消费量大,动物性食物消费量小,植物性食物供能近90%,动物性蛋白少于总蛋白的10~20%;平均每天摄入2000~2400kcal能量,蛋白质仅50g左右,脂肪仅30~40g,膳食纤维充足,但动物来源的铁、钙、维生素A等常会不足。
此类膳食模式易出现蛋白质-能量营养不良,以致体质较弱,营养状况不良,劳动能力降低,但心血管疾病(冠心病、脑卒中)、2型糖尿病、肿瘤等慢性病的发病率较低。 - 经济发达国家膳食结构:以动物性食物为主,营养过剩型膳食
多数欧美发达国家:美国、西欧、北欧诸国。
特点是高能量,高脂肪,高蛋白质,低膳食纤维。粮谷类消费量小,动物性食物及食糖消费量大。平均每天摄入肉类300g,食糖100g,奶和奶制品300g,蛋类50g,蛋白质100g,脂肪130~140g,能量摄入3300~3500kcal。
此类膳食模式容易造成肥胖,高血压,冠心病,糖尿病等营养过剩性慢性病发病率上升。 - 日本膳食结构:动植物性食物摄入较为均衡
保留东方膳食特点,吸收西方膳食长处,少油少盐,多海产品,蛋白质、脂肪和碳水化合物供能比合适。
谷类300~400g,动物性食品100~150g,海产品比例50%,奶类100g,蛋类豆类各50g;能量2000kcal,蛋白质70~80g,动物蛋白占50%,脂肪50~60%;有利于避免营养缺乏或过剩性疾病(心血管疾病、糖尿病和癌症)。 - 地中海膳食结构:富含植物性食物
包括谷类350g、水果、蔬菜、豆类、果仁等,
每日食用适量鱼、禽、少量蛋、奶酪、酸奶;每月食用畜肉的次数不多,主要的食用油是橄榄油;有饮葡萄酒的习惯。突出特点是饱和脂肪酸摄入量低,不饱和脂肪酸摄入量高,含大量复合型碳水化合物,蔬菜、水果摄入量较高。
心脑血管疾病、2型糖尿病发病率低。
- 体质指数(BMI)@
体重kg/[身高m]^2,是目前评价人体营养状况最常用的方法之一。
营养与营养相关疾病
人体能量来源和消耗有哪些方面?试述肥胖人群的能量管理。
(1)能量来源:来自产能营养素(碳水化合物,脂肪和蛋白质)经过生物氧化过程释放的能量
(2)能量消耗:基础代谢,身体活动,食物热效应,特殊生理阶段的能量消耗,如生长发育等
(3)肥胖的营养防治措施
- 控制总能量摄入
- 调整膳食模式和营养素摄入
调整宏量营养素构成比和来源:公认的减肥膳食是高蛋白25,低脂肪25,低碳水化合物膳食50
保证维生素和矿物质的供应
增加膳食纤维的摄入
补充某些植物化学物:异黄酮、皂苷
三餐合理分配及烹调 - 增加体力活动
增加能量消耗,减少脂肪
有助于维持减肥状态,防止反弹
改善代谢紊乱
改善心情和健康状态
预防多种慢性疾病
增加对膳食治疗的依从性
简述与膳食营养有关的高血压危险因素。
- 超重和肥胖
- 矿物质:钠过量,钾不足,钠/钾比值,钙不足,镁不足
- 高盐饮食
- 脂类供能比高
- 过量饮酒
- 其他:海产品、饮茶有助于降低血压
食品卫生学
- 食品安全 # 过程 & 结果安全
指食品无毒、无害,符合应当有的营养要求,对人体健康不造成任何急性、亚急性或慢性危害。
- 食品卫生 # 过程安全
是为防止食品在生产、收获、加工、运输、储存、销售等各个环节被有害物质(包括物理、化学、微生物等方面)污染所采取的各项措施,从而保证人体健康不受损害。
食品污染及其预防
- 食品污染(Food contamination):@
是指各种条件下,导致外源性有毒有害物质进入食品,或食物成分本身发生化学反应而产生有毒有害物质,从而造成食品安全性、营养性和(或)感官性状发生改变的过程。
- 水分活度(water activity,Aw):
食物中微生物可利用的水,指食品中水蒸气分压(P)与同条件下纯水的蒸气压(P0)之比(Aw=P/P0),值越小越不利于微生物增殖。
& 黄曲霉毒素的定义、污染食品的特点、毒性及预防措施?@
- 黄曲霉毒素(aflatoxin, AF):@@
是黄曲霉和寄生曲霉产生的一类代谢产物,具有极强的毒性和致癌性。
黄曲霉毒素污染食品的特点 @
AF主要污染粮油及其制品,其中以玉米、花生、棉籽油最易受到污染,其次是稻谷、大麦、小麦、豆类等
除粮油外,还有干果类食品(如胡桃、杏仁、榛子),动物性食品(如乳及乳制品、肝、干咸鱼等),干辣椒等
家庭自制发酵食品
长江流域以及长江以南的广大高温高湿地区
饲喂AFB1污染饲料生产的牛奶
黄曲霉毒素的毒性 @
- 急性毒性:剧毒物质,中毒性肝炎
- 慢性毒性:动物生长障碍,急性或慢性肝损伤
- 治癌症:公认最强的化学致癌物质,主要是肝癌
黄曲霉毒素的预防措施 @
- 食物防霉:根本措施,干燥,通风
- 去除毒素:挑选霉粒法,碾轧加工法,加水搓洗法,植物油加碱去毒法,白陶土或活性炭物理去除,紫外光照射,氨气处理法
- 制定食物中AF限量标准
什么是食物腐败变质?食物腐败变质是如何产生的?腐败变质的评价指标有哪些?@
- 食品腐败变质(food spoilage):@@
是指食品在以微生物为主的各种因素作用下,其原有的化学性质或物理性质,即食品成分与感官性状的各种变化,降低或失去营养价值的过程。如肉禽蛋鱼的腐臭,粮食的霉变,蔬菜水果的溃烂,油脂的酸败等
食品腐败变质的原因和条件:@
- 微生物
- 食品本身的组成和性质:食品中的酶,营养成分和水分,理化性质(如pH,Aw),状态(外观完好无损)
- 环境因素:温度,适度,氧气,阳光(紫外线)
食品腐败变质的过程:@
- 蛋白质的分解和细菌作用
- 脂肪水解氧化的酸败
- 碳水化合物的分解和酸度升高
食物腐败变质的鉴定指标 @
- 感官鉴定:视觉,嗅觉,触觉,味觉等,颜色变化,组织变软、变粘,腐败变质气味
- 物理指标:低分子物质增多,食品浸出物量,浸出液电导率,折光率,冰点,黏度等
- 化学鉴定
- 挥发性盐基总氮(total volatile basic nitrogen, TVBN):
指食品水浸液在碱性条件下能与水蒸气一起蒸馏出来的总氮量,即在此条件下能形成的氨的含氮物。 - 三甲胺:
是季胺类含氮物质经过微生物还原产生的,新鲜鱼虾等水产品和肉中没有三甲胺,主要用于测定鱼虾等水产品的新鲜程度。 - 组胺:
食品腐败变质时,细菌分泌的组氨酸脱羧酶可使鱼贝类的组氨酸脱羧生成组胺,可引起人类过敏性食物中毒。 - K值(K value):
是指ATP分解的低级产物肌苷和次黄嘌呤占ATP系列分解产物的百分比,主要适用于鉴定鱼类早期腐败。 - pH:一般腐败开始时略微降低,随后上升
- 过氧化值和酸价:过氧化值是脂肪酸败的最早期指标,其次是酸价的上升
- 微生物检验:菌落总数,大肠菌群
防止食品腐败变质的措施
- 化学保藏:盐腌、糖渍,酸渍,防腐剂保藏
- 低温保藏:冷藏,冷冻
- 加热杀菌保藏:常压杀菌,加压杀菌,超高温瞬时杀菌,微波杀菌
- 干燥脱水保藏:日晒,阴干,喷雾干燥,减压蒸发,冷冻干燥等
- 辐照保藏
- N-亚硝基化合物(N-nitroso compounds, NOCs):@@
是一类具有>N-N=O结构的有机化合物,暴露源广泛,多具有遗传毒性和动物致癌性。
N-亚硝基化合物的前体物、毒性和危害预防措施 @@@
N-亚硝基化合物的前体物包括:硝酸盐,亚硝酸盐,胺类物质 @@
- 植物性食品中的硝酸盐,亚硝酸盐
- 动物性食品中的硝酸盐,亚硝酸盐
- 环境和食品中的胺类物质
N-亚硝基化合物的毒性 @@
- 急性毒性:肝脏是主要靶器官,骨髓,淋巴系统
- 致癌作用:强动物致癌物,器官特异性(肝癌,食管癌),多途径摄入,不同剂量具有致癌作用(剂量-反应关系)
- 致畸作用
- 致突变作用
N-亚硝基化合物的预防措施 @@
- 防止食物被微生物污染
- 改进食品加工工艺
- 施用钼肥
- 阻断亚硝基化反应:维生素C,E,酚类,黄酮类化合物
- 制定食品中允许量标准,并加强监测
食品添加剂及其管理
- 食品添加剂:@@@
为改善食品品质和色、香、味,以及防腐、保鲜和加工工艺需要而加入食品中的人工合成或天然物质。
食品添加剂使用的基本要求
- 不应对人体产生任何健康危害;
- 不应掩盖食品腐败变质;
- 不应掩盖食品本身或加工过程中的质量缺陷,或以掺杂、掺假、伪造为目的而使用食品添加剂;
- 不应降低食品本身的营养价值;
- 在达到预期效果的前提下尽可能降低在食品中的用量:
各类食品卫生及其管理
粮豆的主要卫生问题
- 真菌及其毒素的污染
- 农药残留
- 其他有害化学物质的污染
- 仓储害虫
- 其他问题:自然陈化,有毒植物种子的污染,无机夹杂物的污染,掺杂掺假
粮豆的卫生管理
- 粮豆的安全水分,真菌毒素限量
- 安全仓储的卫生要求:入库前检查,仓库合规,清洁卫生,温度湿度,监测
- 运输、销售过程的卫生要求
- 控制农药残留
- 防治无机有害物质和有毒种子的污染
蔬菜、水果的主要卫生问题
- 细菌和寄生虫污染
- 有害化学物质污染:农药,工业废水,亚硝酸盐
蔬菜水果的卫生管理
- 防治肠道致病菌和寄生虫卵的污染
- 施用农药的卫生要求
- 工业废水灌溉的卫生要求
- 储藏的卫生要求
肉类的主要卫生问题
- 腐败变质(spoilage):肉类腐败变质的过程 @@
宰后畜肉从新鲜到腐败要经僵直、后熟、自溶和腐败四个过程
- 僵直(rigor):@
刚宰杀的畜肉中糖原和含磷有机化合物在组织酶的作用下分解为乳酸和游离磷酸,使肉的pH下降,酸度增加。宰后1.5小时(夏季)/3.5小时(冬季),肌凝蛋白达到等电点后凝固,导致肌纤维硬化出现僵直,此时肉有不愉快气味,肉汤浑浊,味道较差,不宜直接用作烹饪原料。 - 后熟(after ripening):
僵直后,肉内糖原继续分解为乳酸,pH进一步下降,使肌肉结缔组织变软并具有一定弹性,表面蛋白凝固形成一层干膜,组织微生物侵入的过程。此时肉松软多汁,滋味鲜美。 - 自溶(autolysis):
宰杀后的畜肉在常温下存放,其组织酶在无菌条件下仍然可以继续活动,分解蛋白质、脂肪而使畜肉发生自溶。变质程度不严重时,这种肉必须经过高温处理后才可使用。 - 腐败(putrefaction):
自溶为细菌的入侵和繁殖创造了条件,细菌的酶使蛋白质、含氮物质分解,使肉的pH上升的过程。
- 人畜共患传染病:炭疽等
- 人畜共患寄生虫病
- 原因不明死畜肉
- 兽药残留
食用油脂的主要卫生问题 @
- 油脂酸败(oil rancidity):@@
油脂和含油脂高的食品在不当条件下存放过久,会呈现出变色、变味等不良感官性状和化学变化的现象。
评价油脂酸败状况的卫生学指标有:酸价,过氧化值,羰基价,丙二醛 - 食用油脂污染和天然存在的有害物质
油脂污染物:黄曲霉毒素B,苯并(a)芘,砷、铅、镍等有害元素,农药残留,微生物
油脂中的天然有害物质:棉酚,芥子油苷,芥酸,反式脂肪酸
简述油脂酸败的原因及预防措施 @
(1)油脂酸败的原因
- 油脂纯度不高,含有较多水分和杂质
- 储存不当,接触氧气,日光,高温等
- 不饱和脂肪酸含量越高的食品越容易氧化
(2)油脂酸败的预防措施 - 保证油脂的纯度:精炼
- 防止油脂自动氧化:避免金属离子污染,密封断氧,低温,避光
- 应用抗氧化剂:人工合成抗氧化剂,维生素E
- 商业无菌(commercial sterilization):
罐头食品经过适度热杀菌后,不含有致病性微生物,也不含有在通常温度下能在其中繁殖的非致病性微生物,同时破坏食品中的酶类,达到长期储存目的的状态。
& 罐头食品变质的特征表现,简单介绍其分类 @
- 胖听(swelling):@
由于罐头内微生物活动或化学作业产生气体,形成正压,使一端或两端外凸的现象。
- 化学性胖听:金属罐受到酸性内容物的腐蚀产生大量氢气而膨胀,叩击呈鼓音,穿洞时有气体逸出,但无腐败气味。一般不宜食用。
- 生物性胖听:由于杀菌不彻底残留的微生物,或罐头有裂缝,从外界进入的微生物,在罐内生长、繁殖、产气造成的。罐头两端凸起,保温实验胖听增大,叩击有明显鼓音,穿洞时逸出的气体有腐败味,此类罐头禁止食用。
- 物理性胖听:多由于装罐过满或者罐内真空度过低引起的胀罐,一般叩击呈实音,穿洞无气体逸出,可食用。
- 平酸腐败(flat-sour spoilage):@
由可以分解碳水化合物,并且产酸不产气的平酸菌引起的,表现为罐头内容物酸度增加,而外观完全正常的一种常见的腐败变质。平酸腐败的罐头应该销毁,禁止食用。
食源性疾病及其预防
- 食源性疾病(foodborne disease):@@
通过摄食进入人体内的各种致病因子引起的、通常具有感染性质或中毒性质的一类疾病。
- 人兽共患传染病(anthropzoonoses):指人和脊椎动物之间自然感染与传播的疾病。
- 食物过敏:(food allergy):@@
也称食物的超敏反应,是指摄入体内的食物中的某组成成分,作为抗原诱导机体产生免疫应答而发生的变态反应性疾病。
- 食物中毒(food poisoning):@
是指摄入含有生物性、化学性有毒有害物质的食物或把有毒有害物质当作食物摄入后出现的非传染性急性或亚急性疾病。
食物中毒的发病特点:
- 发病潜伏期短,来势急剧,呈暴发性,短时间内可能有多数人发病
- 发病与食物有关,病人有统一有毒食物史,切断食物供应后流行终止
- 中毒病人临床表现基本相似,胃肠道症状为主
- 一般情况下,人间无直接传染
食物中毒调查的目的是什么?叙述食物中毒现场调查的程序和方法?
食品中毒调查处理程序及现场调查基本任务。
食物中毒报告包括哪些内容?试述食物中毒调查的程序和注意事项。
举例说明细菌型和毒素型食物中毒的发病机制、临床表现及其预防重点的差异?
金黄色葡萄球菌的致病机制,流行病学特点及预防措施
食品安全性风险分析和控制
什么是危害识别?在食品安全风险评估中如何进行危害识别?
食品安全监督管理
食品安全法律法规体系构成 @
- 食品安全法律:宪法,一般法(刑法,民法,刑事、民事、行政诉讼法),专门法(食品安全法);
- 食品安全法规:行政法规,地方法规;
- 食品安全规章:部门规章,地方规章;
- 食品安全标准;
- 其他规范性文件:地方食药和卫生部分的管理办法和规定等;
- 食品安全标准:@@@
是指对食品中具有与人类健康相关的质量要素和技术要求及其检验方法、评价程序等所作的规定。
食品安全标准的性质
- 政策法规性
- 科学技术性
- 强制性
- 社会性
- 经济性
食品安全标准的意义
- 食品安全标准是食品安全法律法规体系的重要组成部分
- 食品安全标准是食品安全法制化管理的重要依据
- 食品安全标准是维护国家主权、促进食品国际贸易的技术保障。
按标准发生作用的范围或其审批权限的分类 @
- 食品安全国家标准
- 食品安全地方标准
- 企业标准
食品安全标准的制定依据 @
- 法律依据:《食品安全法》和《标准化法》;
- 与国际标准协调一致性
- 科学技术依据
食品安全标准的主要技术指标
- 严重危害人体健康的指标:致病微生物与毒素,有毒有害化学物质,放射性污染物等;
- 反映食品可能被污染及污染程度的指标:菌落总数,大肠菌群等;
- 间接反映食品安全质量发生变化的指标:水分,含氮化合物,挥发性盐基总氮等;
- 营养指标:各种营养素含量;
- 商品质量指标
食品中有毒有害物质限量标准的指定
- 确定动物最大无作用剂量:NOAEL;
- 确定人体可耐受摄入量
- 确定每日总膳食中的允许含量
- 确定每种食物肿的最大允许量
- 指定食品中有毒有害物质的限量标准
食品安全监督管理的原则:
- 预防为主
- 风险管理
- 全程控制
- 社会共治
食品良好生产规范(good manufacture practice, GMP):@@@
是为保障食品安全、质量而制定的贯彻食品生产全过程的一系列措施、方法和技术要求。危害分析关键控制点(HACCP):
是一种食品安全保障体系,为保障食品安全,对食品生产加工过程中造成食品污染发生或发展的各种危害因素进行系统和全面的分析,确定能够有效预防、减轻或消除危害的加工环节(即“关键控制点”),进而在关键控制点对危害因素进行控制,同时监测控制效果,发生偏差时予以纠正,并随时对控制方法进行矫正和补充。(P515)

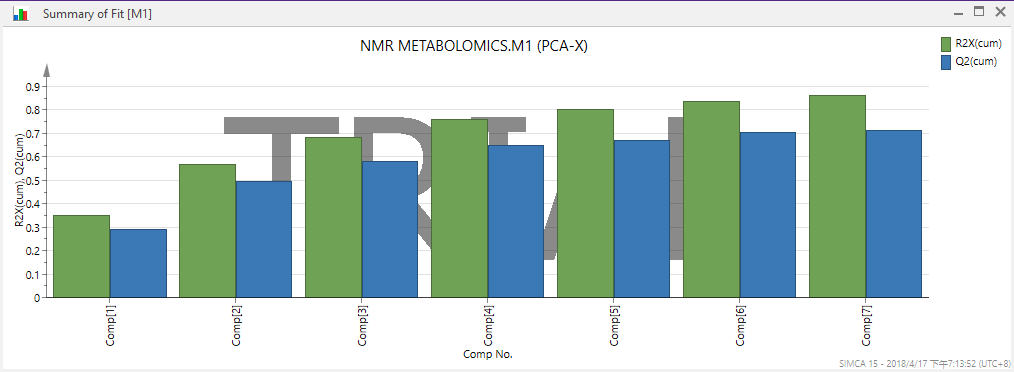
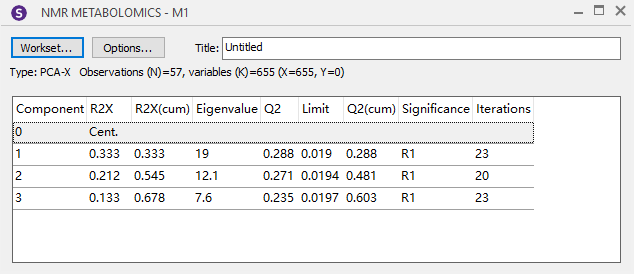
 、
、